Part 1: Foundations of LLMs and Healthcare AI
LLM basics and exploring common healthcare tasks and datasets
LLMs Meet Healthcare: Understanding the Fundamentals #
There are many things to learn when it comes to LLMs and healthcare! We will focus on the very basics and provide additional information that you can use to dive deeper!
Let’s dive right in!
Learning Objectives #
- Understand what LLMs are and how they work at a high level
- Explore common healthcare applications for LLMs
- Survey key healthcare datasets and their characteristics
- Identify unique challenges in healthcare AI
LLM Basics #
Large language models (LLMs) are language models trained with self-supervised machine learning on a vast amount of text, designed for natural language processing tasks, especially language generation. They are deep neural networks that are millions or billions of gigabytes in size and trained on enormous amounts of text data. LLMs have shown to be very powerful in various natural language tasks including generating summaries, answering questions, or completing text based on a given prompt.
Tokenization #
The way that computers are able to work with text is pretty simple. As machine learning algorithms process numbers rather than text, the text must be converted to numbers. In the first step, a vocabulary is decided upon, then integer indices are arbitrarily but uniquely assigned to each vocabulary entry, and finally, an embedding is associated to the integer index. For example, the tokenizer used by GPT-3 would split tokenizer: texts -> series of numerical "tokens" as

Inner Workings of LLMs #
LLMs predict text one token at a time, where each new word depends on all the previous words in the sequence. At its core, this process is entirely probabilistic: the model calculates probability distributions over its entire vocabulary for what word should come next, then samples from those probabilities.
Every aspect of LLM behavior emerges from these probability calculations. When a model seems “confident” or “uncertain,” that is reflected in how concentrated or spread out its probability distributions are. When it generates creative versus factual content, it ss operating in different regions of probability space. Even seemingly deterministic outputs are actually the result of probability sampling - the model might assign 80% probability to one word and 20% to alternatives, but it still has to choose based on those probabilities.
This probabilistic foundation explains both the power and limitations of LLMs. Their ability to generate coherent, contextually appropriate text comes from learning incredibly complex probability patterns across vast amounts of text. But their occasional hallucinations, inconsistencies, and inability to truly “know” facts also stem from this same probabilistic nature. They are essentially very sophisticated probability machines rather than knowledge databases or reasoning engines.
The quality of the outputs from LLMs are sensitive to how prompting is done. Zero-shot prompting involves giving no examples for in-context learning while few-shot prompting involves adding example inputs and outputs to guide the model towards higher quality text outputs. To increase the quality of outputs, developers often further train the models via fine-tuning or instruction-tuning with supervised machine learning to increase the instruction-following abilities of these models.
The recent advances in LLMs were possible with a very famous architecture known as transformers.
What Are Transformers? #
Transformers are a type of model that excel at processing sequences of data, such as sentences in a text. This architecture was introduced by Google researchers in 2017 at NeurIPS conference in their landmark paper named “Attention Is All You Need.”1
The attention mechanism is the core innovation that makes transformers so powerful and efficient. Unlike previous architectures such as recurrent neural networks (RNNs) that processed text sequentially, attention allows transformers to directly relate any word in a sequence to any other word, regardless of distance. This happens through a mathematical process where each word creates “queries,” “keys,” and “values” essentially asking “what should I pay attention to?” and getting weighted responses from every other word in the sequence.
What makes attention revolutionary is that it is computed in parallel rather than step-by-step. Traditional RNNs had to process “The cat sat on the mat” word by word, with information about “cat” potentially degrading by the time they reached “mat.” Attention lets the model instantly connect “cat” and “mat” with equal clarity, capturing long-range dependencies that were previously difficult to learn.
The “self-attention” variant used in transformers is particularly elegant. Each word attends to all words in the same sequence, creating rich contextual representations. When processing “bank,” the attention mechanism automatically figures out whether nearby words suggest a financial institution or a river’s edge. Multi-head attention runs several of these processes in parallel, allowing the model to simultaneously track different types of relationships (e.g., syntactic, semantic, positional, and more). This parallel, direct-connection approach is what enables transformers to scale effectively and understand complex language patterns that require integrating information across long contexts.

Some examples of well-known transformer-based LLMs are GPT-4, Claude 4 Sonnet, Llama, and Mistral.
Challenges in NLP for Healthcare #
Although general LLMs are powerful in generating texts, they often lack the specialized knowledge or abilities that are required for health and medical-specific tasks.
NLP tasks for healthcare are different from general NLP tasks for the following reasons:
- Medical jargon and domain specific adaption
- Requires precision and accuracy
- Ethical, legal, and safety concerns due to high risk setting
- Requires clinical/healthcare expert input and feedback
Hallucinations (generating inaccurate information) and challenges in evaluating medical LLMs are some of the other challenges listed by the visualization below:
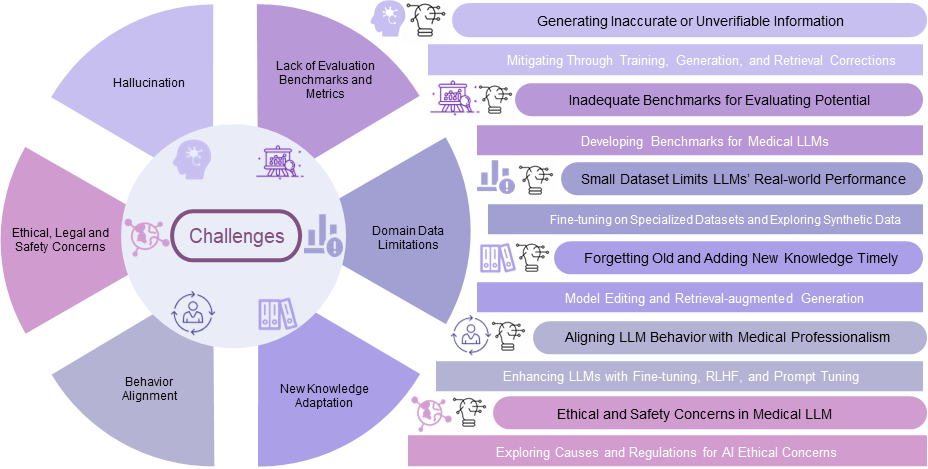
Due to LLMs needing domain adaptation, researchers and developers have pre-trained or fine-tuned LLMs on biomedical text (clinical notes, medical research articles, etc) to create medical-specific LLMs.
Over the years, there have been numerous biomedical LLMs developed such as BioBERT, ClinicalBERT, MedPaLM2, and MEDITRON. Some LLMs have shown to perform quite well on US Medical License Exam-style MedQA benchmark dataset. MedPaLM2 has even achieved an accuracy of 86.5% which is about human expert performance. Although medical LLMs performing at expert level on these benchmark tasks is amazing, there is still much room for improvement as benchmark performance do not directly translate to good performance on real-world tasks.
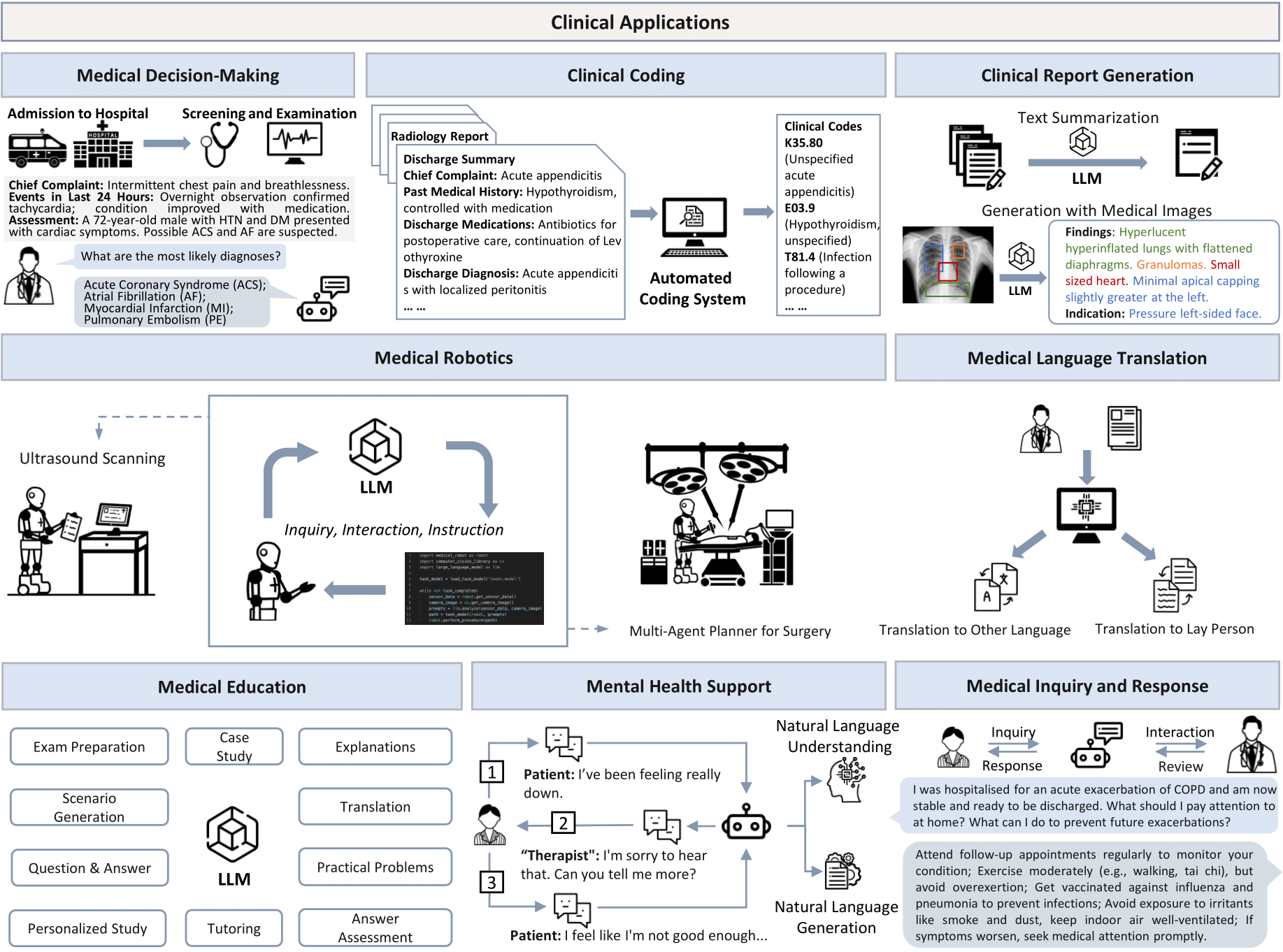
Healthcare Tasks That LLMs Are Good At #
LLMs can provide value in healthcare by increasing quality but decreasing cost to ensure better patient and care team experience. Specifically, LLMs can reduce healthcare’s administrative burden. This allows clinicians time to actually do healthcare rather than administrative work.
Examples:
- Clinical note summarization
- Medical literature review and synthesis
- Patient education material generation in simplified language
- Drug interaction checking
- Symptom assessments
- Medical coding assistance (ICD-10, CPT codes) which is useful for billing
Healthcare Datasets #
To train and evaluate LLMs on healthcare-specific tasks, we need healthcare datasets. Healthcare datasets can come in many forms. Some are for pre-training or fine-tuning while some are for evaluating the performance of the LLMs on healthcare tasks.
The following lists some of the most common healthcare datasets:
- MIMIC-III/IV: ICU patient de-identified data Paper Dataset
- PubMed: Medical literature abstracts Datset
- Medical imaging datasets: ReXrank - Radiology Report Generation
- ADE: automatic extraction of drug-related adverse effects from medical case reports Paper
Exercise! #
Dive deep into three distinct healthcare natural language processing (NLP) datasets to understand how they are structured for LLM training or evaluation. Thoroughly understanding the nature of datasets is a key part of being a responsible researcher or developer of healthcare AI and we want you to practice this important analytical skill. Data is a fundamental part of any AI development which cannot be overlooked.2
If you are an LLM researcher for a university lab or a healthcare startup, what are important features and characteristics of a dataset that you should know before using them in your projects? Understanding the data is really important since data is never perfect. There can be human errors in data collection and annotation. The data might not necessarily be what you may be looking for. This exercise can provide you with some guidance on what to look out for when investigating a new dataset.
By the end of this activity, you will be able to:
- Identify key structural differences between healthcare AI datasets
- Understand how dataset design influences LLM training approaches
- Analyze language complexity across different medical specialties
📊 The Three Datasets #
ReXrank - Radiology Report Generation
Domain: Medical imaging and diagnostic reporting
Task: Generate radiology reports from chest X-ray images
Link: ReXrank DatasetSUMPUBMED - Biomedical Literature Summarization
Domain: Scientific literature processing
Task: Create concise summaries of PubMed research articles
Link: SUMPUBMED DatasetDDI Corpus - Drug-Drug Interaction Extraction
Domain: Pharmacology and drug safety
Task: Identify and classify drug interactions from text
Link: DDI Corpus
🔍 Your Mission: Dataset Detective #
Step 1: First Impressions (10 minutes)
For each dataset, spend a few minutes exploring and jot down your initial observations. The links to the dataset are provided above. You are not execpted to download and write code to understand the data.
Quick Analysis Template:
Dataset: [Name]
First impression: [What strikes you immediately?]
Text length: [Short sentences, paragraphs, full documents?]
Vocabulary: [Technical terms, everyday language, specialized jargon?]
Structure: [Formatted, free-text, structured fields?]
Step 2: Deep Dive Analysis (30 minutes)
Complete this detailed comparison table:
| Aspect | ReXrank (Radiology) | SUMPUBMED (Literature) | DDI Corpus (Drug Interactions) |
|---|---|---|---|
| Data Source | Chest X-ray reports from hospitals | PubMed biomedical articles | DrugBank + MedLine abstracts |
| Input Format | ? | ? | ? |
| Output Format | ? | ? | ? |
| Text Length | ? | ? | ? |
| Language Style | ? | ? | ? |
| Domain Vocabulary | ? | ? | ? |
| Key Challenges | ? | ? | ? |
| Evaluation Metrics | ? | ? | ? |
Helpful Guide to complete the comparison table:
Find and analyze specific examples from each dataset:
Medical Terminology Challenge
- ReXrank: Find 3 radiology-specific terms (e.g., “pneumothorax”, “cardiomegaly”)
- SUMPUBMED: Find 3 research methodology terms (e.g., “randomized controlled trial”)
- DDI Corpus: Find 3 pharmacological terms (e.g., “pharmacokinetic”, “bioavailability”)
Sentence Structure Analysis
Compare sentence patterns. The following are just examples of what you may expect:
- ReXrank: “The lungs are clear without focal consolidation, pneumothorax, or pleural effusion.”
- SUMPUBMED: “This systematic review examined 15 randomized controlled trials involving 3,247 participants.”
- DDI Corpus: “Concurrent use of warfarin and aspirin may increase the risk of bleeding complications.”
What do you notice about:
- Sentence length?
- Certainty vs. uncertainty language?
- Active vs. passive voice?
🧠 Critical Thinking Questions #
Why do you think ReXrank includes both “findings” and “impressions” sections? What’s the difference between describing what you see vs. what you conclude?
SUMPUBMED articles have different levels of summaries? How does this compare to news article summarization?
The DDI Corpus annotates 5 types of interactions (Mechanism, Effect, Advice, Int, Negative). Why not just “interaction” vs “no interaction”? What does this tell us about the complexity of drug safety?
LLM Training Challenges
- Which dataset would be hardest for an LLM to master and why?
- Consider: vocabulary complexity, reasoning requirements, safety implications
Real-World Impact
Rank these applications by potential impact if an AI system made errors:
- Missing a drug interaction
- Misreading a chest X-ray
- Poorly summarizing a research paper
What safeguards would you implement for each system before clinical deployment?
You can find more details on Transformers and the paper via these blog posts: The Illustrated Transformer and Annotated Transformer ↩︎
This exercise was created with the assistance of Claude AI. ↩︎